All Stories

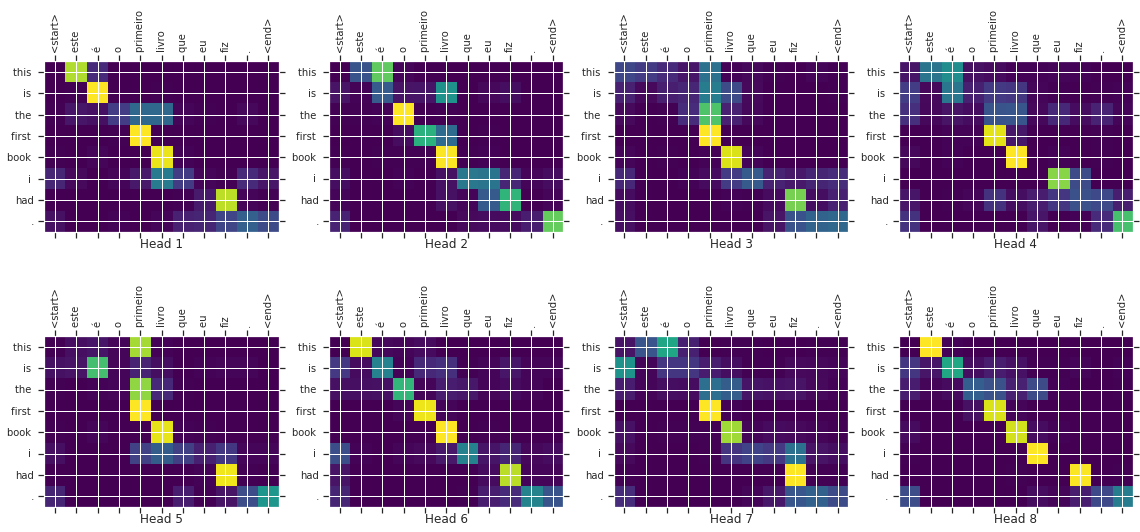
Min-Max Loss, Revisiting Classification Losses
In continuation to my Partial Tagged Data Classification post, We formulate a generic loss function applicable to all task(classification, metric learning, clustering, ranking, etc)
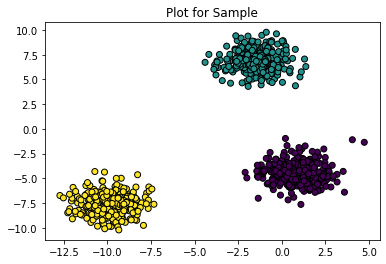
Multi Single Class Learning, Classifying Partially Tagged Data
Machine Learning requires a large amount of clean data for the models to be trained. But that’s rarely the case in reality. A Scenario in real life is clicks/likes data,...