MLAI Blog
Yet Another Machine Learning and Data Science Blog
Category Attentions
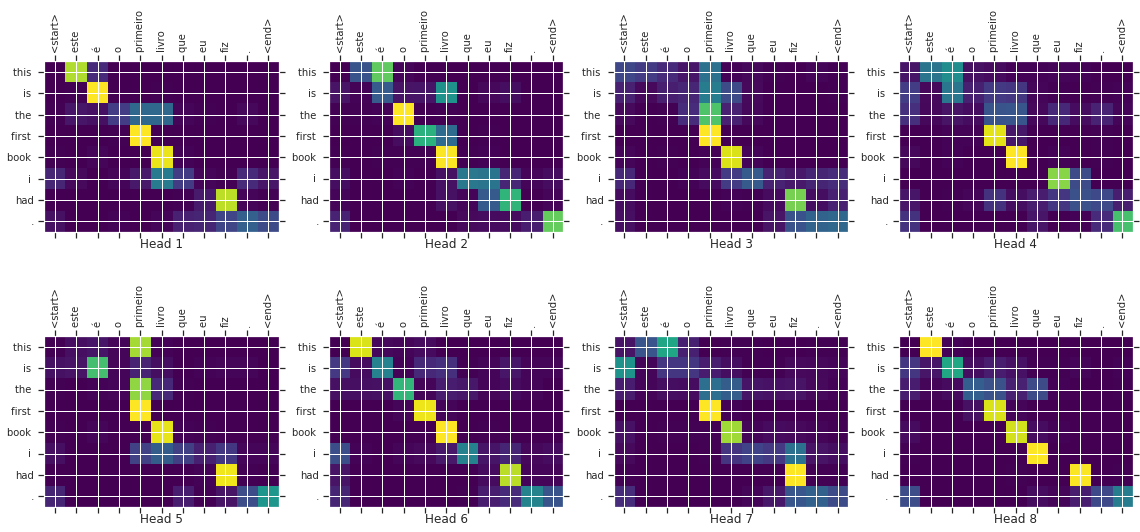
Attention is the mightiest layer so far, which symbolizes its parent paper that “Attention is all you need” in true sense. Almost all tasks, be it images, voice, text, reasoning,...
Attention is the mightiest layer so far, which symbolizes its parent paper that “Attention is all you need” in true sense. Almost all tasks, be it images, voice, text, reasoning,...
Category Deep Learning
Self-Supervised training is a eureka concept, where machines don’t need labels to learn concepts, It started with a lack of tagged data and solution being self-supervised training. However, in recent...
Deep learning has reached its heights while Reinforcement learning is yet to find its moment. But today we will take a problem from the famous deep learning space and map...
We left last post Min Max Loss Classification Example on the promise to demonstrate a self supervised classification example. What is Self Supervised Classification. Self Supervised Classification is a task...
In continuation to my Partial Tagged Data Classification post, We formulate a generic loss function applicable to all task(classification, metric learning, clustering, ranking, etc)
Machine Learning requires a large amount of clean data for the models to be trained. But that’s rarely the case in reality. A Scenario in real life is clicks/likes data,...
Attention is the mightiest layer so far, which symbolizes its parent paper that “Attention is all you need” in true sense. Almost all tasks, be it images, voice, text, reasoning,...
Category NLP
Attention is the mightiest layer so far, which symbolizes its parent paper that “Attention is all you need” in true sense. Almost all tasks, be it images, voice, text, reasoning,...
Category Loss Function
We left last post Min Max Loss Classification Example on the promise to demonstrate a self supervised classification example. What is Self Supervised Classification. Self Supervised Classification is a task...
In continuation to my Partial Tagged Data Classification post, We formulate a generic loss function applicable to all task(classification, metric learning, clustering, ranking, etc)
Machine Learning requires a large amount of clean data for the models to be trained. But that’s rarely the case in reality. A Scenario in real life is clicks/likes data,...
Category Classification
In continuation to my Partial Tagged Data Classification post, We formulate a generic loss function applicable to all task(classification, metric learning, clustering, ranking, etc)
Category Self Supervised Learning
Self-Supervised training is a eureka concept, where machines don’t need labels to learn concepts, It started with a lack of tagged data and solution being self-supervised training. However, in recent...
We left last post Min Max Loss Classification Example on the promise to demonstrate a self supervised classification example. What is Self Supervised Classification. Self Supervised Classification is a task...
Category Reinforcement Learning
Deep learning has reached its heights while Reinforcement learning is yet to find its moment. But today we will take a problem from the famous deep learning space and map...
Category Pretraining
Self-Supervised training is a eureka concept, where machines don’t need labels to learn concepts, It started with a lack of tagged data and solution being self-supervised training. However, in recent...
Category Dropout
Self-Supervised training is a eureka concept, where machines don’t need labels to learn concepts, It started with a lack of tagged data and solution being self-supervised training. However, in recent...
Category VAE
Self-Supervised training is a eureka concept, where machines don’t need labels to learn concepts, It started with a lack of tagged data and solution being self-supervised training. However, in recent...